欧洲杯体育这种想象允许贪图单位以全速加载权重-开云(中国)Kaiyun·官方网站 - 登录入口

近日,Moonshot的Kimi K2在GroqCloud平台上推出了预览版块,诱惑了多数建设者的良善。他们纷纷酷爱,Groq是若何作念到让领有1万亿参数的模子运行得如斯赶紧的。
传统硬件常常让建设者堕入两难境地:追求更快的推理速率常常意味着质料的和洽,而追求高精度则可能导致无法收受的蔓延。这种量度的根源在于,GPU架构主要针对测验责任负载进行优化。比较之下,Groq的LPU(逻辑处置单位)专为推逸想象,大约在保捏高质料的同期,扬弃形成蔓延的架构瓶颈。
Groq通过其特有的TruePoint数值技能,冲突了传统加速器的局限。传统加速器通过激进量化来提高速率,这频繁意味着模子被压缩到INT8或更低精度,从而引入积攒罪恶,导致质料下落。而TruePoint技能仅在不影响准确度的区域缩短精度,麇集LPU架构,大约在保捏高精度数值的同期,确保模子质料。TruePoint体式复旧100位中间积攒,提供充足的规模和精度,不管输入位宽若何,都能末端无损积攒。这意味着权重和激活函数不错以较低精度存储,而扫数矩阵运算则以全精度试验,然后确认下流罪恶敏锐度弃取性地量化输出。
Groq的编译器政策性地应用不同精度,举例,在需要高准确性的谛视逻辑中使用FP32,在搀和群众(MoE)权重中使用块浮点而不影响放心性,以及在容错层中存储FP8激活。这种精度遏抑政策使得速率比BF16提高了2至4倍,同期在MMLU和Humaneval等基准测试中保捏了准确率。
内存架构方面,传统加速器沿用为测验想象的内存层级结构,依赖DRAM和HBM行动主存储,这些存储介质在每次权重索取时都会引入数百纳秒的蔓延。这关于需要按规章试验层且运算强度较低的推理任务来说,是不利的。而Groq的LPU集成了数百兆片上SRAM行动主权重存储器,显赫缩短了造访蔓延。这种想象允许贪图单位以全速加载权重,并通过将单层拆分到多个芯片上末端张量并行,为快速、可彭胀的推理带来本色上风。
在试验模子方面,GPU架构依赖于动态赞助,这引入了非详情趣蔓延。而Groq的编译器事前贪图扫数这个词试验图,包括芯片间通讯时势,直至单个时钟周期。这种静态赞助扬弃了缓存一致性契约、再行排序缓冲区、规划试验支拨和运行时互助蔓延,末端了详情趣试验。这进一步复旧了两项重要优化:无尾蔓延的张量并行和张量并行之上的活水线并行。
Groq的并行政策专注于蔓延优化散播。数据并行通过运行多个模子实例来彭胀朦拢量,适用于提高全体处置才调,但关于单个反映的恭候时期并无匡助。而张量并行通过将单个操作散播在多个处置器上来缩短蔓延,这关于及时应用至关蹙迫。Groq的LPU架构专为张量并行而想象,将每一层分歧到多个LPU上,从而加速单次前向传递的速率。
Groq还选拔了规划解码技能,把握较小的“草稿”模子展望畴前令牌序列,并在较大的目的模子中进行考据。在传统硬件上,考据要领频繁受内存带延期定,而在Groq的LPU上,通过活水线并行不错更高效地处置规划性token批次的考据,从而加速处置速率。
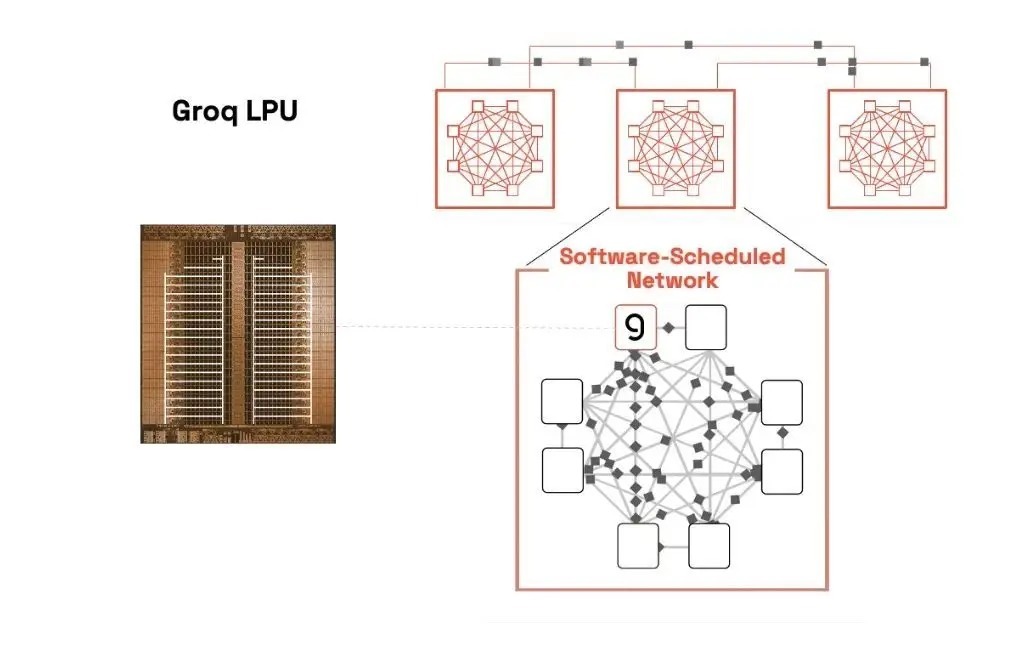
软件赞助收罗方面,Groq使用准同步芯片间契约来扬弃时钟漂移,并将数百个LPU对皆,使其充任单个中枢。这么,软件编译器不错准确展望数据到达时期,复旧时序推理。周期性软件同步不仅复旧贪图赞助,还复旧收罗赞助,使Groq大约像单核超等集群雷同运行,幸免了传统架构中的复杂互助问题。
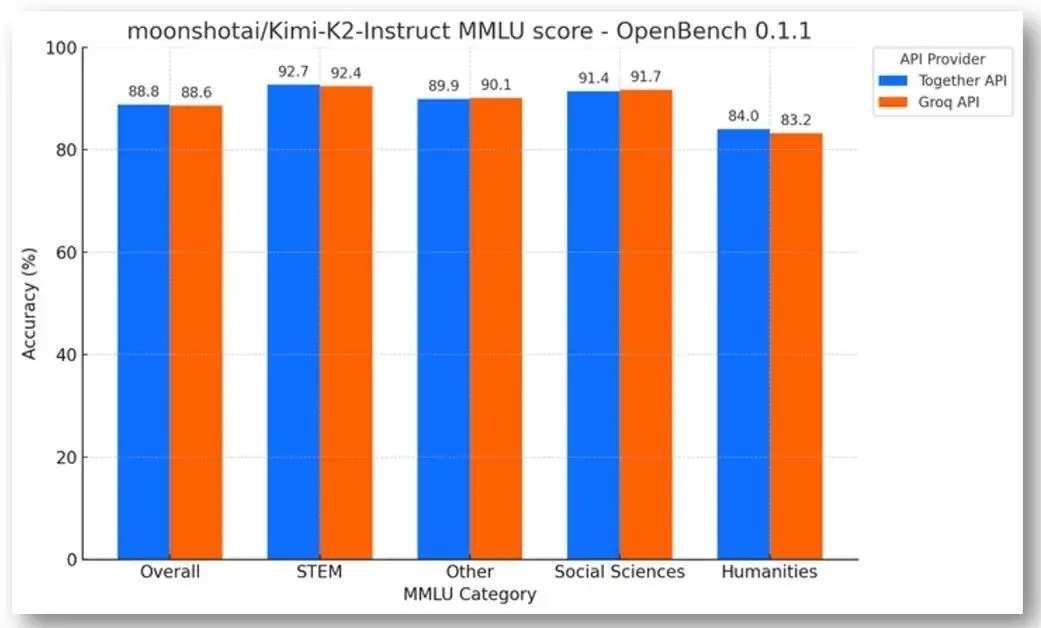
在基准测试方面,Groq发达出了超卓的性能。他们发布了OpenBench,一个与提供商无关的、面向大型说话模子(LLM)的绽放评估框架。在Groq和基于GPU的API提供商上运行Kimi-K2-Instruct的OpenBench 0.1.1 MMLU末端,效果走漏准确率得分很高,充分展现了Groq堆栈的浩荡功能。
Groq从零初始构建推理系统欧洲杯体育,勤劳速率、规模、可靠性和资本效益。正因如斯,他们大约在短时期内让Kimi K2的性能末端显赫提高。Groq高度怜爱建设者反馈和本色性能,麇集行业跳跃的想象和严格的技能基准,竭力于于提供极致的AI推理体验。他们将陆续加速硬件和软件的建设,让建设者大约专注于快速构建应用。
